
GitHub is the most popular platform for open source code. GitHub was already massively popular before Microsoft purchased it in 2018. Since the acquisition however, a plethora of new features have been introduced. One of those features is in beta: Copilot. Copilot is an AI pair programmer that helps prototype, learn, and write code. In this article, I examine what Copilot is, how Copilot performs on simple tasks in Python, and when Copilot should be used.
Some people hear “AI pair programmer” and ideas of the terminator surface to mind. Copilot is not “Artificial General Intelligence”, but it’s not unintelligent either. In fact, Copilot is better at writing in some programming languages than some junior programmers. The backbone of Copilot is OpenAI’s Codex which is capable of producing code in a number of languages.
OpenAI Codex is most capable in Python, but it is also proficient in over a dozen languages including JavaScript, Go, Perl, PHP, Ruby, Swift and TypeScript, and even Shell. Codex
Natural Language Processing
To understand what Copilot is, it’s necessary that you have some understanding of a field called Natural Language Processing (NLP). NLP aims to train computers to read and write like humans. NLP models are created for various purposes - chatbots, Q&A, virtual assistants. In fact, you’ve probably used many NLP models in your daily life. Ever used an autocomplete service like the one in gmail? That’s an NLP model.
Copilot is a special variant of an NLP model (GPT-3) that is trained on freely available, open source code that could’ve been written by anyone with a GitHub account.
What data has GitHub Copilot been trained on? GitHub Copilot is powered by OpenAI Codex, a new AI system created by OpenAI. It has been trained on a selection of English language and source code from publicly available sources, including code in public repositories on GitHub. Copilot splash page
Training is the process by which an AI model learns to perform some task. An extremely over-simplified version of the process of “training” the model behind Copilot would be:
- Give the model a task in English - i.e. “write the power function”
- Copilot, after reading a bunch of code, tries to solve the task.
- An error is calculated between what Copilot produced and what the desired answer is.
- That error is then provided to Copilot so that it can make adjustments (i.e. learn).
This process is repeated for millions of lines of code totaling close to 200Gb of code. The model itself has 12 billion parameters which can be altered during the course of training. Below is a visual of what this training process looks like for the model Copilot is based on (GPT-3).
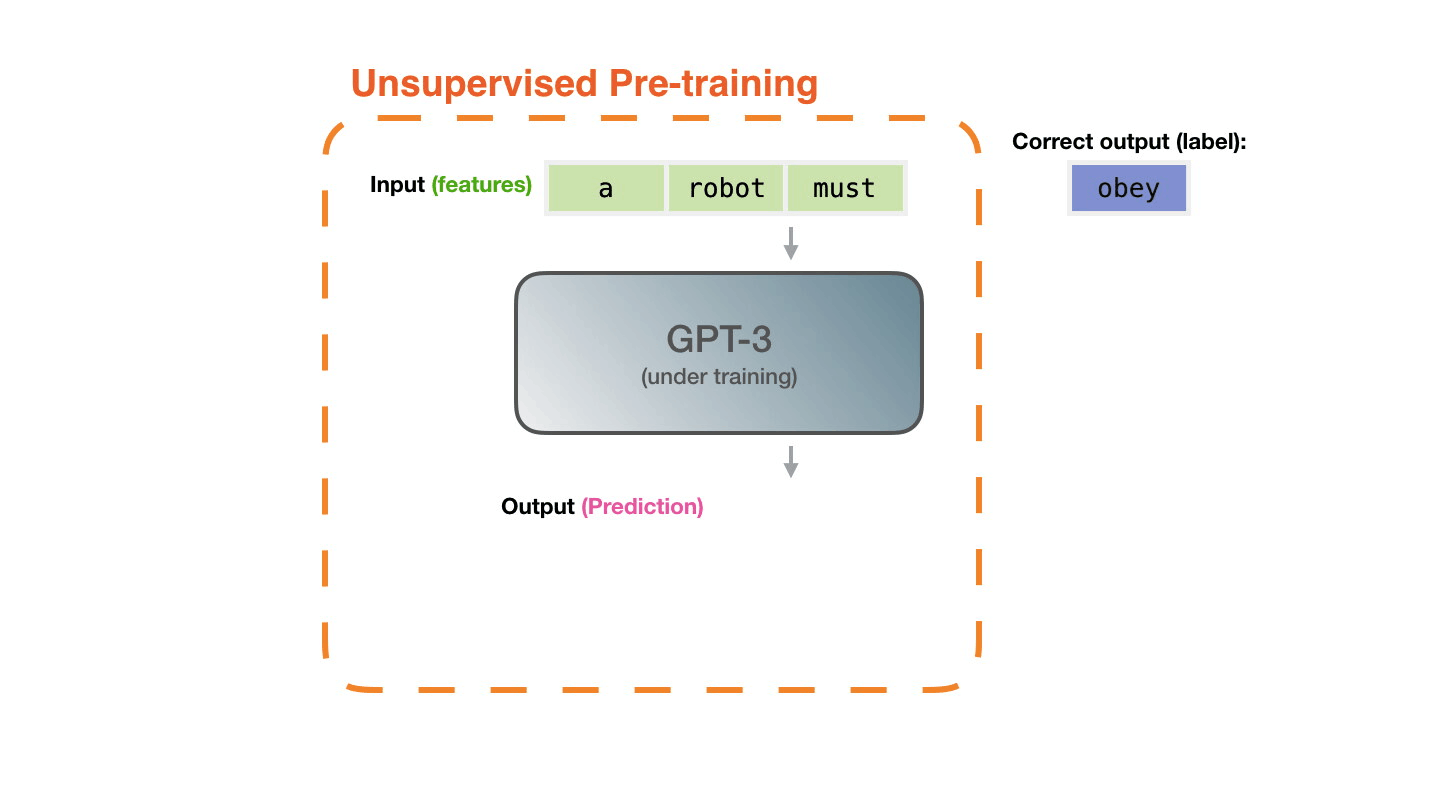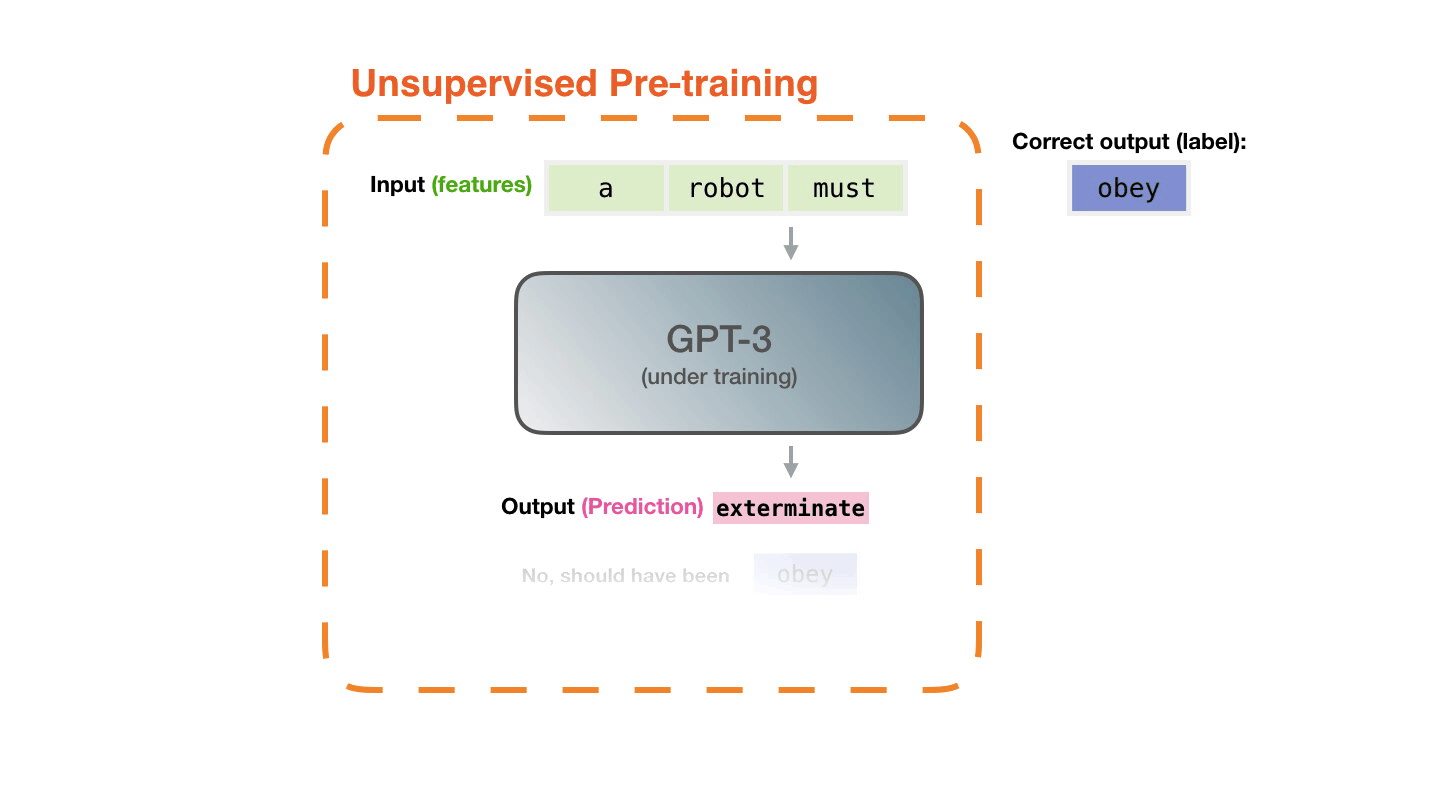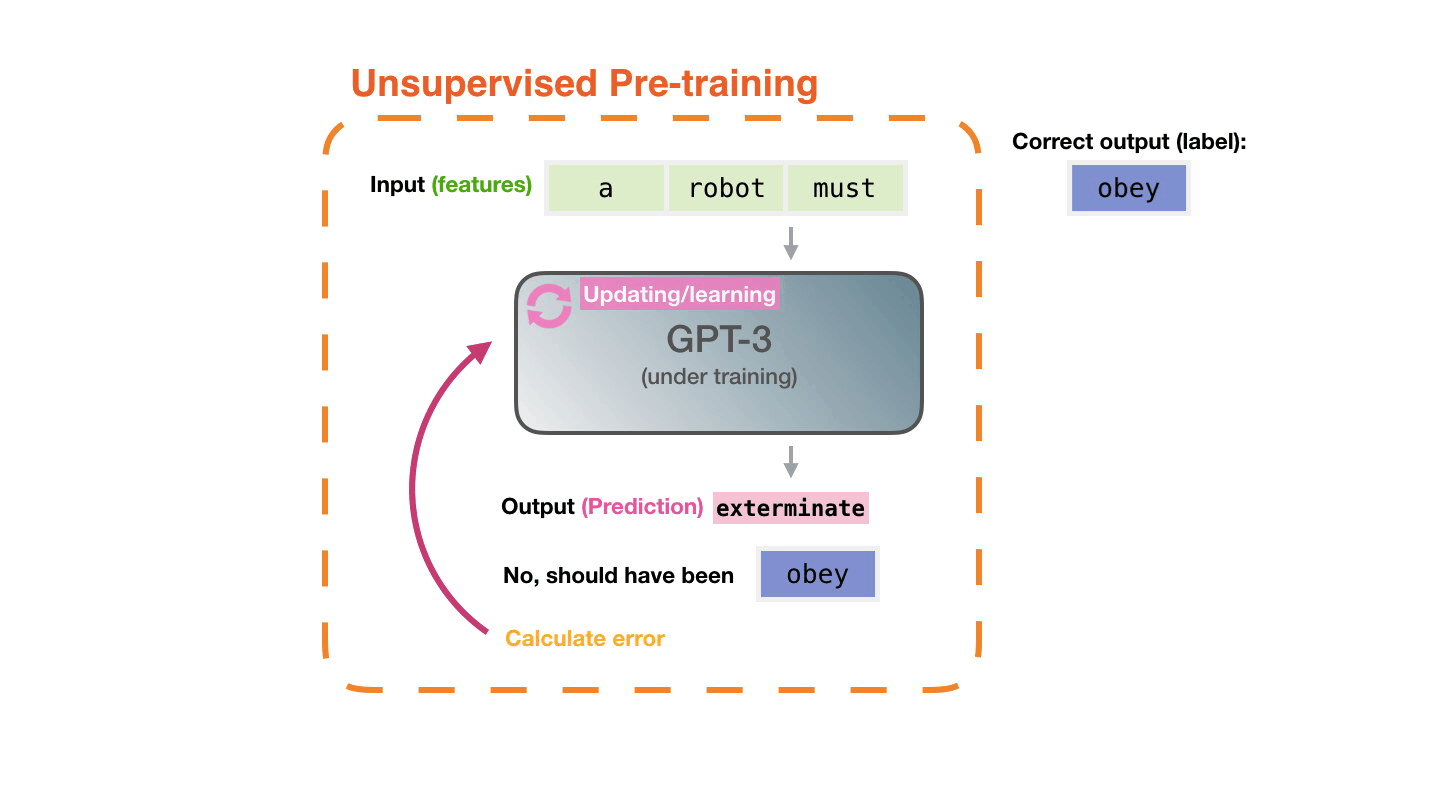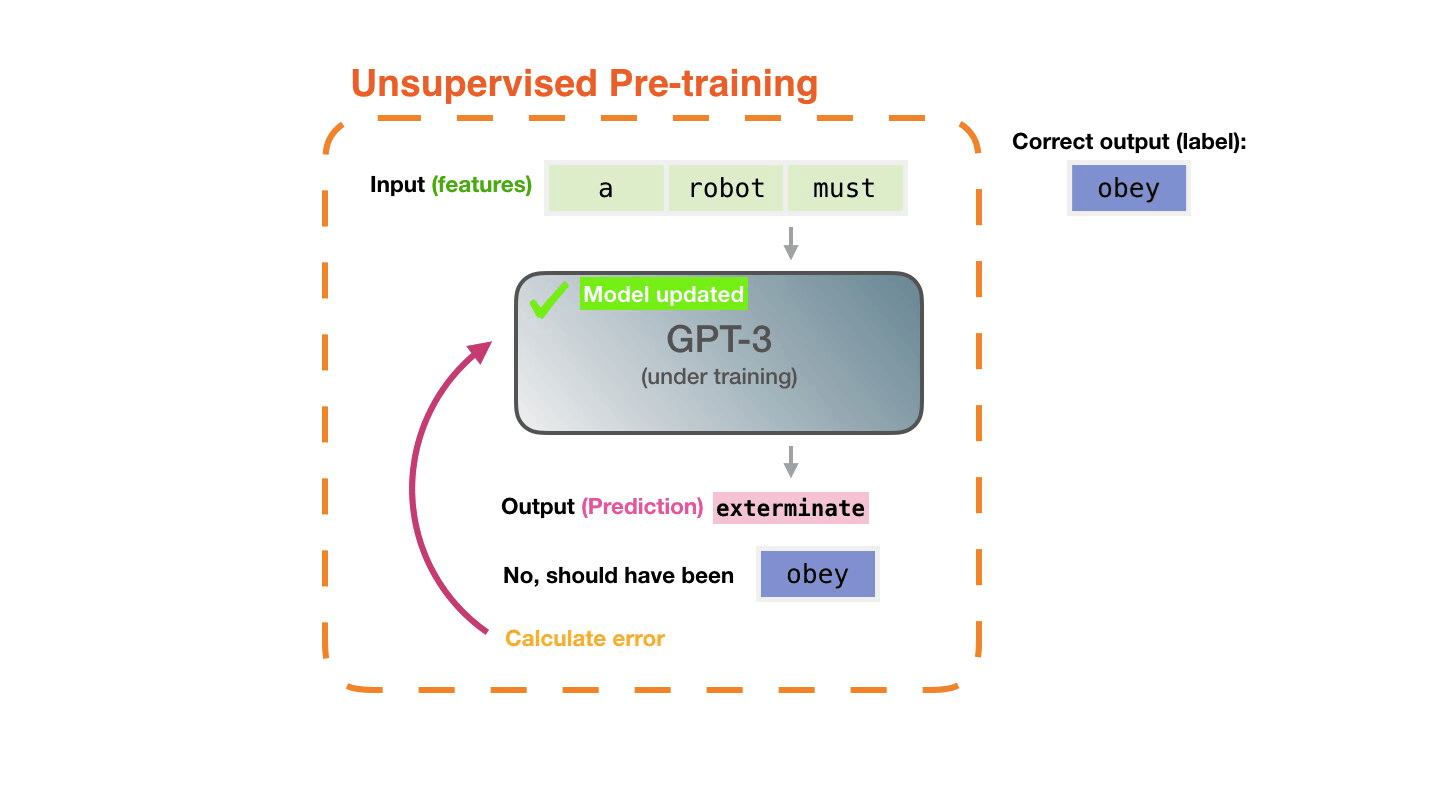
If you want to learn more about the GPT-3 training process, I took the above GIF from this article which provides some nice visualizations. This paper covers the creation of GPT-3, and there are always many good ones on PapersWithCode.
To summarize, Copilot uses an NLP model, Codex, trained on open source code. The objective of Copilot is to produce correct code given some English language prompt describing the problem to solve. Copilot knows how to do this since Codex has been trained on large amounts of open source code across many languages.
Now that you know what Copilot is, let’s put Copilot to the test and see how it performs on some simple problems.
Using Copilot
Once enabled in your VSCode environment, Copilot is triggered to provide suggestions after prompts or while you’re typing. For example, let’s give Copilot the example prompt I listed above: “write the power function”.
This is what we will provide Copilot to start:
# write the power function
def power(x, n):
Seems like a simple enough task right? Well, let’s look through some of the suggestions that Copilot provides.1
First, Copilot suggests a simple solution to the power function. You can tell it’s a suggestion because it’s greyed out below the code that I’ve provided. To accept, hit tab and the code suggested will be entered.
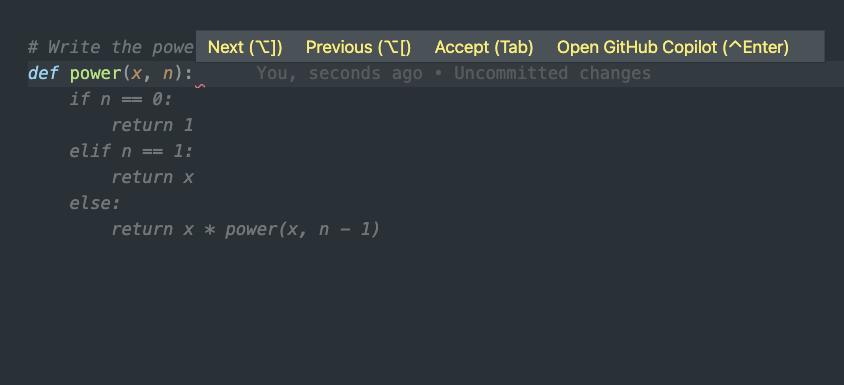
The first solution is far from the optimal way to solve the power function. This solution recursively accumulates the answer by multiplying the result of each recursive function call by the argument x.
Looking through the samples we see that Copilot knows some other, more efficient ways to solve this problem. Here’s the second suggestion Copilot provides.
# write the power function
def power(x, n):
if n == 0:
return 1
elif n % 2 == 0:
return power(x, n // 2) ** 2
else:
return x * power(x, n // 2) ** 2
This variant provides a solution of O(logn) complexity 2 which is much faster than the O(n) (linear) solution that Copilot first suggested. Hence, we will call this one fast_power and the first solution Copilot provided simple_power
x = 2, n = 500
536 function calls (15 primitive calls) in 0.001 seconds
ncalls tottime percall cumtime percall filename:lineno(function)
10/1 0.000 0.000 0.000 0.000 power.py:21(fast_power)
500/1 0.000 0.000 0.000 0.000 power.py:3(simple_power)
After profiling this function, and one more variant that Copilot provides, we see that indeed the second variant is much faster.3
So that’s it, AI is going to replace developers!
Not so fast!!
Before we throw up our hands, let’s dig into the solutions that Copilot provides.
While Copilot was able to suggest a more performant solution, all the solutions it provides have one massive issue. If you haven’t noticed it by now, don’t feel bad. I royally screwed this question up in an interview one time too.
What if the input n is a negative?
If n is negative, all the solutions suggested by Copilot break. A better way to solve this problem is to address the input prior to performing the actual computation as follows:
def correct_power(x, n):
def _correct_power(x, n):
if n == 0:
return 1
half = _correct_power(x, n//2)
if n % 2 == 0:
return half * half
else:
return half * half * x
if n < 0:
x = 1/x
n = -n
return _correct_power(x, n)
Now, some C heads are going to say thats not it! What if N>1000! shakes fist Yes, this isn’t the complete solution, but for the purposes of this demonstration, it’s good enough.
This solution is as performant as the one suggested by Copilot (runs with O(logn) complexity) but can also handle negative inputs.
x = 2, n = 500
554 function calls (24 primitive calls) in 0.001 seconds
ncalls tottime percall cumtime percall filename:lineno(function)
10/1 0.000 0.000 0.000 0.000 power.py:21(fast_power)
500/1 0.000 0.000 0.000 0.000 power.py:3(simple_power)
1 0.000 0.000 0.000 0.000 power.py:30(correct_power)
10/1 0.000 0.000 0.000 0.000 power.py:32(_correct_power)
Why Copilot isn’t taking anyone’s job
As you can see from the example above, Copilot doesn’t always provide the correct answer. It may help you get started, but the task of creating correct, efficient software is still very much at the mercy of the developer.
One might say, “but what if you gave copilot information about handling negative inputs”? While Copilot is able to adjust and does output something sensible, YOU, the programmer, still need to be aware of such implementation details.
Copilots ability and shortcomings both arise from the data it was trained on: open source repositories of code. Think about it. Did the OpenAI developers have time to filter through and only select the code they thought was written well or correct?? Absolutely not. There are millions of repositories and that would take forever. Even though Copilot uses a state of the art AI model, and uses a brilliant training process, it’s still guaranteed to occasionally write code that is either incomplete, incorrect, or inefficient. This is because it was trained on code with all of those qualities. Anyone can push their code to GitHub, even the most junior developers. That code, written by those junior developers, is part of the corpus of text that Copilot is trained to produce.
The point of this example is this: despite massive advances in AI-assisted programming, the onus is still on the programmer, not the AI.
What is Copilot useful for?
Despite the pitfalls listed above, Copilot can be extremely useful. I’ve personally been using Copilot for a number of side projects and kept track of when I found it to be useful. Below I’ll list some examples of times when I’ve found Copilot to be the most useful.
Boilerplate code
Apple makes it easy to export the health data you have stored on your iPhone/watch. I recently exported my workout data, and was exploring it in a Jupyter notebook.4 After cleaning up the data with a library I found on GitHub, I decided to let Copilot try to put the data into a Pandas DataFrame.
This is the function it produced with the prompt: “Write a function that takes in a dictionary data and populates a Pandas DataFrame with workout data”
def create_workout_dataframe(data):
"""
Creates a dataframe with the following columns:
- date
- duration
- distance
- heart_rate
- steps
- calories
- comment
"""
df = pd.DataFrame(columns=['date', 'duration', 'distance', 'heart_rate', 'steps', 'calories', 'comment'])
for i in range(len(data)):
date =
duration = data[i]['duration']
distance = data[i]['value']
heart_rate = data[i]['value2']
steps = data[i]['value3']
calories = data[i]['value4']
comment = data[i]['comment']
df.loc[i] = [date, duration, distance, heart_rate, steps, calories, comment]
return df
Although this function doesn’t run correctly, it does provide a way in which to think about extracting data into a Pandas DataFrame.5
With some quick edits, this function extracts the data correctly and creates a DataFrame with my lackluster workout data.
def create_workout_dataframe(data):
"""
Creates a dataframe with the following columns:
- date
- duration
- duration_unit
- distance
- distance_unit
- energy_burned
- energy_unit
"""
df = pd.DataFrame(columns=['date',
'duration',
'duration_unit',
'distance',
'distance_unit',
'energy_burned',
'energy_unit'])
for i, workout in enumerate(data.workouts):
date = workout.created_at
duration = workout.duration
duration_unit = workout.duration_unit
distance = workout.distance
distance_unit = workout.distance_unit
energy_burned = workout.energy_burned
energy_unit = workout.energy_burned_unit
df.loc[i] = [date, duration, duration_unit, distance,
distance_unit, energy_burned, energy_unit]
return df
Despite changing some of the fields and correcting some of the bugs, the overall structure of the code is the same. Even thought this is not how I would’ve written this function, it’s still very useful when writing “throwaway” or “boilerplate” code which is all too common in exploratory data analysis.
Learning libraries
Copilot can be very useful in surfacing new ways to use libraries you’ve been using for some time. For example, I use the Pandas library in Python all the time. Whenever I plot a simple part of a DataFrame, I usually use Matplotlib.
For example, using the workout DataFrame created by the function above, I would’ve written something like this in order to create a Scatter plot of calories burned per workout.
plt.scatter(workout_df["duration"], workout_df["energy_burned"])
However, when I was using Copilot, it suggested using the plotting functionality built into Pandas DataFrames directly.
workout_df.plot(kind='scatter', x="duration", y="energy_burned", figsize=(12, 6))
Despite using Pandas all the time, this functionality is not something I was using. Additionally, with the DataFrame method, Pandas adds in axis and names that would’ve otherwise had to have been manually specified in Matplotlib.
Copilot can be really useful in situations where you are unfamiliar with a framework. This makes intuitive sense because the code Copilot has learned from is probably better than your first attempt with it.6 Even in the case where you’ve used it a thousand times, like the example above, it just might teach you a new way to use it.
Conclusion
Copilot is wicked cool. There is no doubt about that. Despite its apparent shortcomings, Copilot has the potential to be a revolutionary step forward in software development. Nat Friedman, the former CEO of GitHub, captured this sentiment well in a comment on HackerNews by saying:
We think that software development is entering its third wave of productivity change. The first was the creation of tools like compilers, debuggers, garbage collectors, and languages that made developers more productive. The second was open source where a global community of developers came together to build on each other’s work. The third revolution will be the use of AI in coding. The problems we spend our days solving may change. But there will always be problems for humans to solve. Nat Friedman
Thanks for reading! If you liked it, please share!
-
On a Mac use option-] to cycle through the Copilot suggestions ↩
-
If you don’t know what big-O notation is, it’s essentially a way for programmers to communicate “how slow could this possibly run” or rather “whats the runtime in the worst case scenario in relation to the input of the function” ↩
-
Here I’m using a tool in the Python standard library called cProfile which can be found here: https://docs.python.org/3/library/profile.html ↩
-
Fair warning: don’t do this unless you want to be depressed about how little you’ve worked out during Covid. ↩
-
One thing to note here is that I had already been working in this Jupyter Notebook for a while. Copilot seems to do much better when the file you are working in is populated with code and comments. ↩
-
Obviously there is no 1-to-1 mapping here because Copilot is generating this code, but still I think this imagery is helpful in understanding where Copilot excels. ↩
Comments