

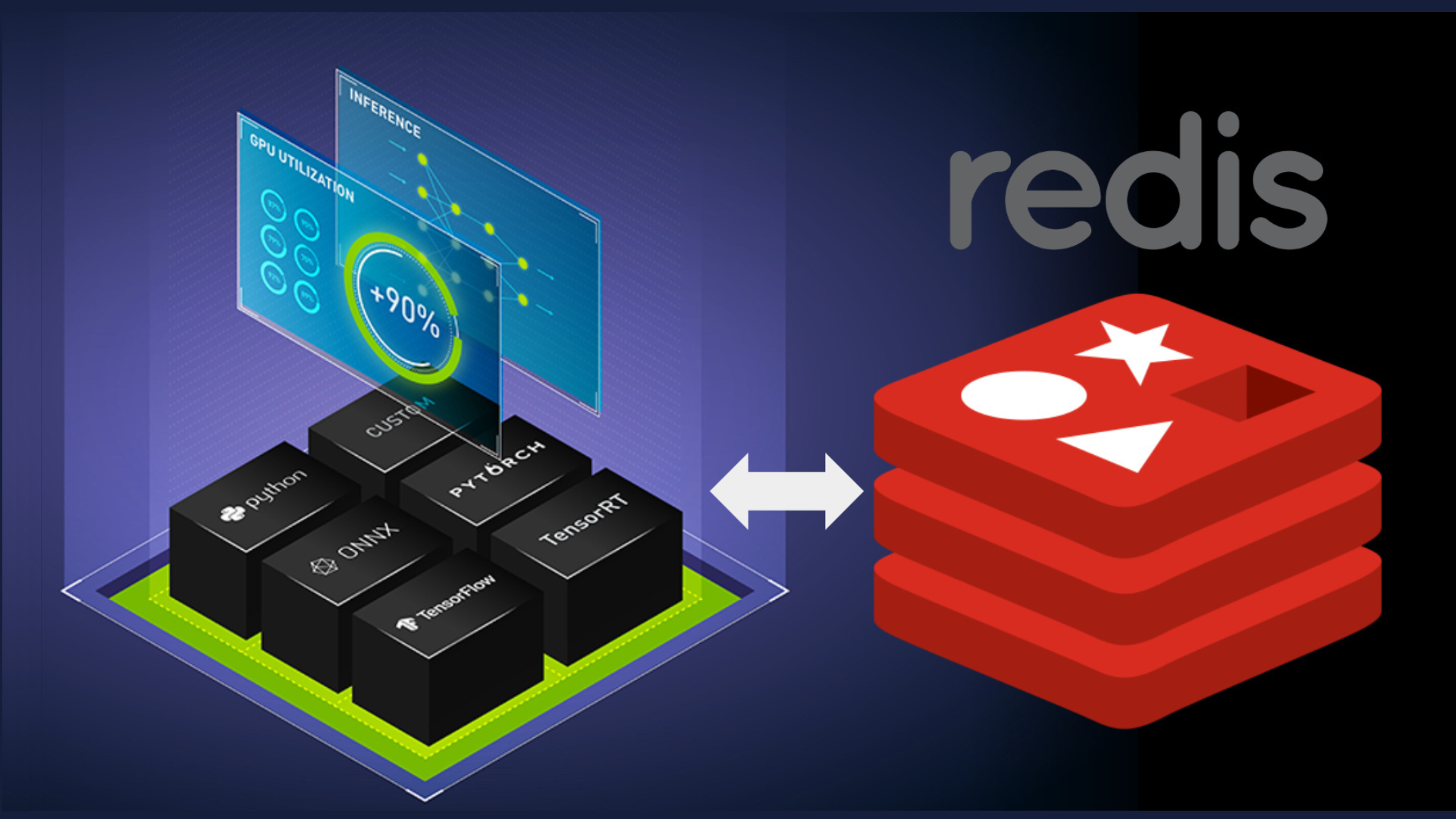
Steve Lorello (Redis), Ryan Mccormick (NVIDIA), and I recently wrote an article about how to use Redis as a cache for inference responses in NVIDIA Triton. This post links to the blog post and the accompanying code.
Top Posts
Latest Posts

In this talk, I chat with Relevance AI startup founder Jacky Koh, research leader Jonathan Cohen from NVIDIA, and venture capitalist George Mathew of Insight Partners, about their experiences in the generative AI space. We also discuss the LLM stack, market, and try to predict the future of the field.

The second half to my talk at LLM in Production conference about using Vector Databases for Large Language Models.